About / A Propos
À propos du processus de migration numérique
Ce site permet un accès numérique à des descriptions archivistiques qui n'existaient auparavant que sous forme d'inventaires PDF statiques. Afin de migrer ces "fonds" historiques complexes vers un environnement Omeka S interrogeable, nous avons mis en œuvre un pipeline rigoureux d'extraction, de transformation et de chargement (ETL), piloté par un agent de codage spécialisé basé sur une interface en ligne de commande (CLI).
Notre objectif principal tout au long de cette conversion a été de maintenir une intégrité absolue des données grâce à un processus "sans perte" et traçable. Nous avons respecté des protocoles stricts garantissant qu'aucune donnée archivistique n'a jamais été inventée ; si un champ de métadonnées spécifique était absent du PDF source, il reste marqué comme "null" dans notre base de données au lieu d'être déduit par inférence. De plus, chaque nœud de données analysé conserve son texte brut d'origine, garantissant que l'information structurée est toujours traçable jusqu'au document source.
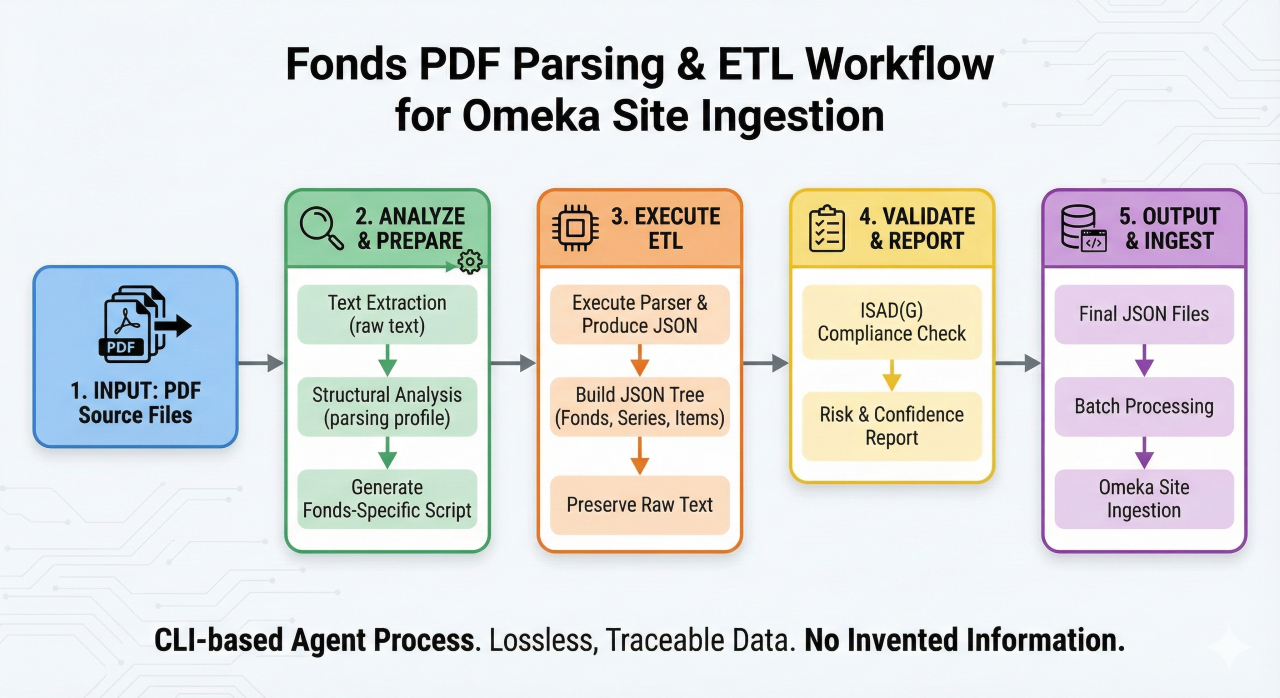
Le flux de travail typique impliquait le traitement indépendant de chaque PDF, consistant d'abord à extraire son texte brut, puis à analyser sa structure pour créer un profil d'analyse et un script de génération uniques. Après l'extraction, la conformité des données aux normes archivistiques (ISAD(G)) a été vérifiée et les risques potentiels ont été évalués avant l'ingestion finale.
Le diagramme ci-dessous visualise ce parcours complet, du fichier source non traité au document numérique accessible.
About the Digital Migration Process
This site grants digital access to archival descriptions that previously existed solely as static PDF inventories. To migrate these complex historical "fonds" into a searchable Omeka S environment, we executed a rigorous extraction, transformation, and loading (ETL) pipeline driven by a specialized CLI-based coding agent.
Our primary directive throughout this conversion was to maintain absolute data integrity through a "lossless" and traceable process. We adhered to strict protocols ensuring that no archival data was ever invented; if a specific metadata field was not present in the source PDF, it remains marked as null in our database rather than being inferred. Furthermore, every parsed data node retains its original raw text, ensuring that structured information is always traceable back to the source document.
The typical workflow involved treating each PDF independently, first extracting its raw text and then analyzing its structure to build a unique parsing profile and generation script. Following extraction, the data was checked for compliance with archival standards (ISAD(G)) and assessed for potential risks before final ingestion.
The diagram below visualizes this complete journey from unprocessed source file to accessible digital record.